














一、IA32处理器简介
IA32系列处理器
保护地址方式&实地址方式
IA32系列CPU有3种工作方式:保护方式(包含一种子工作方式:虚拟8086方式)、实地址方式、系统管理方式
(1)保护方式
保护方式是IA32系列处理器的常态工作方式,可以发挥全部性能和特点 ,windows、Linux都运行于保护方式
全部32根地址线有效,可寻址4GB物理地址空间
支持存储器分段管理 & 可选的存储器分页管理机制
支持虚拟存储器的实现,用于指定存储单元的是面向虚拟存储器的虚拟地址
提供完善的保护机制
支持操作系统实现多任务管理
支持虚拟8086方式
(2)实地址方式
实地址方式是最初的工作方式:
开机/重新设置系统后,IA32工作于实地址方式
很久以前8086/8088等只支持实地址方式
实地址方式下只能访问最低1MB物理地址空间(00000H-FFFFFH)
实地址方式下只支持存储器分段管理,且每个段大小限于64KB,段内有效地址范围0000H-FFFFH。不支持分页
储管理机制。可以认为实地址方式下用于指定要访问存储单元的线性地址就是 ...

一、CPU简介
目标代码 ==目标代码/目标程序:由机器指令组成的程序==
CPU只能执行机器指令
高级语言编写的程序,最后都要转换成机器指令组成的程序,即目标代码,这样才能执行
目标代码是二进制编码的
程序编译过程
CPU基本功能 CPU的基本功能包括:==执行机器指令、暂存少量数据、访问寄存器==
执行机器指令 机器指令:CPU能直接识别并执行的指令 指令集:一款CPU能执行的全部指令的集合 指令的分类: (1)数据传送指令 (2)转移指令 (3)处理器控制指令 (4)其他指令 暂存少量数据 大部分指令是对数据进行运算和处理。运算数据和运算结构存在 (1)寄存器(CPU中) (2)存储器中(内存) 利用CPU内寄存器存取运算数据和结果效率最高。汇编器会充分利用CPU中仅有的寄存器,编写汇编时也要注意 访问存储器 存储器:CPU可以直接访问的计算机系统的物理内存 由机器指令组成的目标程序存储于存储器中,部分待处理数据也是 存储器(内存)由一系列存储单元线性组成,最基本的存储 ...

编译原理
未读
研究LALR的原因
规范LR分析表的状态数偏多
LALR特点
LALR和SLR的分析表有同样多的状态,比规范LR分析表要小得多
LALR的能力介于SLR和规范LR之间
LALR的能力在很多情况下已经够用
LALR分析表构造方法
通过合并规范LR(1)项目集来得到
合并核心项
写出自动机,发现有共同点
合并之后的
分析表
该报错的依旧是报错
是否会引起冲突
对于 LR(1) 文法, 合并得到的 LALR(1) 分析表是否会引入冲突?
· 不会引入移入/归约冲突
假设合并后出现冲突,[A → α·, a] 与 [B → β · aγ, b]
则在 LR(1) 自动机中, 存在某状态同时包含 [A → α·, a] 与 [B → β · aγ, c] (c随便是什么)
· 可能会引入归约/归约冲突
总结语法分析:
自顶向下: LL(1)
自底向上: LR(0), SLR(1), LALR(1), LR(1)
LL(1), LR(0), SLR(1), LALR(1), LR(1)文法之间的关系
https://blog ...


构造SLR分析表本质上就是构造一个基于文法LR(0)项目的LR(0)自动机。LR(0)项目,LR(0)自动机
LR(0)项目在右部的某个地方加点的产生式加点的目的是用来表示分析过程中的状态
LR(0)自动机根据文法LR(0)项目构造识别可行前缀的DFA
LR(0)项 => LR(0)自动机文法的所有LR(0)项构成一组规范LR(0)项集,这些规范项集对应LR(0)自动机的状态。
构造SLR分析表的两大步骤
从文法构造识别可行前缀的DFA
从上述DFA构造分析表
接下来就是把增广文法分写来写成I0
接下来就是根据I0不断推进,并在对应的action,goto表格中记录下来
如果出现动作冲突,那么该文法就不是SLR(1)的
SLR(1)和LR(0)的语法分析表的区别就是,SLR(1)仅在FOLLOW集下写ri,而LR(0)是在action整行写下ri
以上就是构建SLR分析表的步骤,严格来时,SLR分析表是一种特殊的LR(0)分析表,在后面我们还会了解到更为特殊的规范LR方法,通常情况下称为LR(1)文法

编译原理
未读一、LR语法分析器模型
二、LR语法分析算法输入:一个输入串w和一个LR语法分析表
输出:如果w在L(G)中,输出w的自底向上的语法分析过程中的归约步骤;否则给出错误提示
方法:最初,语法分析器栈中的内容为初试状态S0,输入缓冲区的内容为w $。然后,执行语法分析程序。
分析实例
LR(0)的自动机
分析表
分析过程
三、LR分析算法的特点
定义LR文法:我们能为之构造出所有条目都唯一的LR分析表。
直观上说,只要存在这样一个从左到右扫描的移入-归约语法分析器,它总是能够在某文法的最右句型的句柄出现在栈顶时识别出这个句柄,那么这个文法就是LR的。
特点集合
栈中的文法符号总是形成一个可行前缀
分析表的转移函数本质上是识别可行前缀的DFA
栈顶的状态符号包含了确定句柄所需要的一切信息
是已知的最一般的无回溯的移进——归约方法
能分析的文法类是预测分析法能分析的文法类的真超集
能及时发现语法错误
手工构造分析表的工作量太大
四、LR分析方法和LL分析方法的比较LR文法 vs LL文法
LR(K)文法:向前看k个输入符号能够知道一个产生式的右部所能推导出的所有 ...
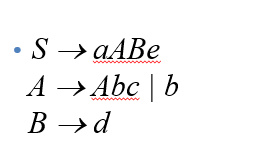
编译原理
未读一、自底向上语法分析
一个自底向上语法分析过程对应于为一个输入串构造语法分析树的过程,它从叶子节点开始,逐步向上到达根节点。即把输入串归约成文法的开始符号。
二、规约
若一个子串和某个产生式的右部匹配,则用该产生式的左部符号代替这个子串。
归约可以看成是推导的逆过程
三、句柄
句型的句柄是和某产生式右部匹配的子串,并且,把它归约成该产生式左部的非终结符代表了最右推导过程的逆过程的一步。
该段文字中蓝色部分就是句柄
如果说文法存在二义性,那么句柄可能不一致
四、用栈实现移进——归约语法分析
移进——归约语法分析是自底向上语法分析的一种形式。
使用栈来保存文法符号,并用一个输入缓冲区来存放将要进行语法分析的其余符号。
移进——归约语法分析的四种动作:
移进:把下一个输入符号移进栈
归约:分析器知道句柄的右端已在栈顶,然后确定句柄的左端在栈中的位置,再决定用什么样的非终结符代替句柄
接受:分析器宣告分析成功
报错:分析器发现语法错误,调用错误恢复例程
下面是一个例子
五、id1 * id + id的归约语法分析
关于这个流程,大家可以仔细关注一下,通过这个流程,应该可 ...

定义对于一个文法G的每一个产生式A->a,进行如下处理:
对于FIRST(A)中的每一个终结符号m,将A->a添加到[A,m]。
如果e在FIRST(A)中,那么对于FOLLOW(A)中的每一个终结符b,将A->a添加到M[A,b]中,如果e在FIRST(a)中,且$在FOLLOW(A)中,也将A->a加入M[A,$]。
通俗一点来讲,就是建立一个通道,即是两个终结符之间通过什么可以完成可达性。
实例
特殊的一个文法的预测分析表有没有多重定义的条目,当且仅当该文法是LL(1)的
如果文法G是左递归或二义的,则M至少含一个多重定义的条目
案例
id + id * id $ 的推导过程 (初始情况)
已匹配
栈
输入
E $
id + id * id $
TE’ $
id + id * id $
FT’E’$
id + id * id $
idT’E’$
id + id * id $
id
T’E’$
+ id * id $
id
E’$
+ id * id $
id
+TE’$
+ id * id $
...

LL文法的两个函数FIRST AND FOLLOW
花了很长时间,终于搞明白了LL文法的FIRST和FOLLOW相关的内容,希望对大家有所帮助
FIRST
对于FIRST(α)我们看产生式头可以推导得到的产生式体中的首个符号集合,即计算FIRST时非终结符号处于产生式的头部。
定义
FIRST(a)被定义为可以从a推导得到的串的首符号的集合,其中a是任意的文法符号串
FIRST(a)={a=>*b…,b是终结符}
如果a=>*e,e也属于FIRST(a)
计算方法
如果X是终结符,那么FIRST(X)=X
如果X->Y1Y2Y3…Yk,且a在FIRST(Yi)中,且Y1=>*e,Y2=>*e,…,Yi-1=>*e,那么a在FIRST(X)中
如果X->e,那么e在FIRST(X)中
例子
FOLLOW
计算FOLLOW时非终结符号位于产生式体中,查看当前产生式体中(或者叫句型的右边部分)非终结符号紧挨着的 终结符号 集合。
定义
FOLLOW(A)被定 ...




